
Venture Bytes #54 - It's the Data, Stupid!
It’s the Data, Stupid!
We could have autonomous vehicles (AV) today, but they will not be safe. In order to have safe AVs, we need about 10 years of data gathering. AVs use a type of artificial intelligence (AI) algorithm called neural networks, and the main characteristic you have to know about neural networks is that they are the most data demanding algorithm out there. Neural networks help computers make statistical predictions about the future based on past experiences, and the past experiences are in fact the data we supply it.
One important phrase to highlight is “statistical predictions,” and as we all know, statistics cannot be correct 100% of the time. Therefore, it all comes down to what the chances of making a mistake are.
We see neural networks applications every day, and they sometimes make mistakes. Depending on the application, those mistakes can be tolerated, like when Netflix suggests a movie to watch that you certainly dislike, but a mistake by an AV can be fatal.
Not Just Data but Type of Data
The more data we feed the algorithm, the greater the accuracy of the algorithm, but why is that? Something that many people get wrong is that the car does not literally understand its surroundings (AI has not reached that point as yet), but gets inputs from sensors like radars and LIDARs to make statistical decisions about its surroundings.
But it is not as simple as just providing any data. Engineers have to decide what type of data will help the algorithm improve its accuracy. As obvious at it seems, more precise data produces more precise driving decisions, but it also takes more time for the computer to process that data.
In our previous article “In the Hunt for The Holy Grail,” we mentioned three sources that generate data: cameras, radars and LIDARs. Since the data from cameras is most precise, we should only use cameras, right? Not really. The following Exhibit 1 illustrates the key aspects of the three sources of data.
An average AV (sensors vary depending on the company) has to process 3.15 GB every second but today’s computers are not that fast, so we not only need data but also a fast computer to process that data. Data from LIDARs and radars are easily processed by the computer since it is being recorded in computer language, but cameras collect pixels, which then have to be translated to a computer language, which requires extra computing power and time. To solve this problem, companies are increasingly adopting LIDARs and radars rather than cameras. That said, Tesla’s decision to depend only on cameras despite its issues seems unreasonable.
Scope is as Much or More Important than Volume of Data
One more factor to consider with statistical models is that the scope of data is as much or more important than the volume of data. Massive amounts of data about the same highway or road will not improve the algorithm’s accuracy by much. The algorithm needs data from different situations since, as mentioned before, the algorithm makes decisions based on past experiences.
An algorithm that has never seen a kid jumping on a pogo stick in the middle of the street may not provide the correct response and that is a risk we cannot take. The algorithm needs a large number of AVs (with a safety engineer until the algorithm’s accuracy meets safety standards) on the roads to collect more data, but current regulations are restrictive in terms of the number of AVs on the road.
The collection of data for multiple “scenarios” is a tedious and laborious task that will take years to gather since there are an “infinite” number of possible scenarios that a car could encounter on the road. Driving applications that will encounter a minimal number of “scenarios” are going to be implemented first. Trucks are ideally suited to be the first since driving on a highway is more monotonous than driving in a major city such as New York City. Accordingly, autonomous trucks will very likely be the first application where human safety drivers will not be present.
While gathering data is critical, it is not going to be easy. At this point the number of AVs collecting data is minimal given the restrictions in most cities. Instead, companies have to rely on simulating different driving situations and conditions. One major challenge is simulating human behavior which, as it turns out sometimes, is not that predictable. Ultimately, simulations are good for improving the accuracy of algorithms, but cannot fully substitute real-life data to move closer to full-proof safe autonomous cars.
Given all the variables and challenges, how many more years before we see a mass roll-out of autonomous cars? From today’s vantage point, the best forecast by market experts is 10 years, and we concur with that projection.
The IPO Juggernaut Rolls On
As we enter the second half of 2019, will the IPO juggernaut continue powering ahead? All key indicators suggest the second half will be equally strong compared to the first half of 2019, with enterprise software/cloud companies leading the charge.
There is a perfect confluence of events underlying this strong IPO market. Against the backdrop of low interest rates, a generally helpful FED, relatively strong GDP growth, investors are hungry for yield and growth stocks given scarce opportunities, and the “fear of missing out on the next big thing”.
• Hunt for Yield. Investors are hungry for yield given low interest rates, with the possibility of further declines.
• Investors Want Growth but Scarcity is a Major Factor. With most of the tech stocks at peak levels and their valuations on the rich side, there is a scarcity factor in the market. As a result, investors are attracted to promising, high growth, disruptive technology stocks coming out of the gate.
• Fear of Missing Out (FOMO). The fear of missing out on the next Workday, Shopify, Coupa, Square and other recent past winners is playing a significant part in keeping the risk-on sentiment alive, in the face of scarce opportunities for yield and growth-at-reasonable-valuations in the market. Additionally, investors are willing to give the benefit of the doubt to transformational stories such as Uber and Lyft, the pullback notwithstanding, and alternate food categories such as Beyond Meat.
Right Place at the Right Time. The average age of the new IPOs (Exhibit 6) is 9 years (8 years without two outliers) which, while slightly above historical average, is the right age to exit the private market. The revenue models are fully baked compared to previous years, and there is a path to profitability, if not profitable already.
• “This Time it is Different.” We believe today’s IPOs are a lot different from the IPOs in the year 2000 for a few reasons. For one, the companies are older so the business models are much better defined. Second, and more important, today’s IPOs are transformational in many respects, disrupting our way of life for the better.
Notable IPOs expected in the second half include a number of enterprise software firms and a handful of high-profile consumer facing companies such as Peloton, Postmates, The We Company and Casper. Two long awaited IPOs, AirBnB and Palantir, pushed out their respective IPOs to early-2020
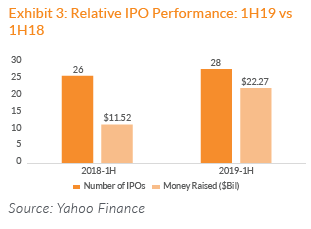
The following charts illustrate the performance of the IPOs in the first half of 2019:


What’s a Rich Text element?
Heading 3
Heading 4
Heading 5
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
Static and dynamic content editing
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
How to customize formatting for each rich text
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.