
Venture Bytes #127: AI Is Ready, Enterprise Data Is Not

AI Is Ready, Enterprise Data Is Not
AI is running into a hard constraint. Enterprise data wasn’t built for it.
Most enterprise knowledge lives in unstructured and multimodal formats like PDFs, Word documents, PowerPoint presentations, videos, call recordings, internal wiki pages, emails, chat messages, among others. Legacy extract, transform, load (ETL) tools are fundamentally ill-equipped to handle these formats effectively. This mismatch has become the central bottleneck to reliable AI, and it’s creating a fertile opening for startups focused on untangling enterprise data at scale.
The scale of unstructured data is massive. Nearly 90% of all enterprise data is unstructured, growing at 55-65% annually, per Congruity360, a Massachusetts-based database management company. This isn't just a technical inconvenience; it's a $3.1 trillion annual cost to the US economy in the form of poor data quality. For individual large enterprises, data quality issues consume an average of 6% of revenue, or roughly $406 million annually.
The promise of retrieval-augmented generation (RAG) systems was supposed to solve this by grounding AI responses in enterprise knowledge. But in practice, RAG systems are only as reliable as the pipelines beneath them. When documents are stale, metadata is missing, formats conflict, or retrieval pulls the wrong context, hallucinations creep back in. Even in well-designed deployments, hallucination rates of 10-15% persist, unacceptable for compliance, finance, healthcare, or core operational workflows.
Various forces are converging to make this a generational opportunity. First of all, enterprise AI disillusionment is on the rise. A recent MIT study found 95% of enterprise gen-AI pilots fail to deliver measurable profit and loss impact. Another survey from Workday found that while 85% reported AI saved them 1-7 hours per week, nearly 37% of those gains were erased by ‘rework’ of correcting errors, rewriting outputs, and manually verifying results. Boards are demanding return on investment on AI deployment and companies are ready to pay premium prices for platforms that solve data entropy.
Second, model commoditization is making data the actual differentiator. As foundation models become more capable and accessible, the competitive advantage shifts to proprietary data and how well it's prepared. Meta's $14.3 billion bet on Scale AI was explicitly about controlling the data pipeline for Llama models.
Finally, regulators and internal risk teams are increasingly expecting companies to trace decisions back to specific documents, data sources, and assumptions. When AI systems rely on opaque, unstructured inputs, that traceability breaks down. As a result, enterprises are prioritizing systems that can clearly tie AI outputs to governed, up-to-date source material.
The upside of untangling unstructured and multimodal data isn’t confined to a single workflow or department. It cuts across nearly every core enterprise function where decisions depend on messy, real-world context.
The most immediate gains show up in industries like financial services, insurance, healthcare, legal services, and large-scale enterprise SaaS. These sectors are document-heavy, process-driven, and risk-sensitive. Contract analysis, claims processing, compliance reviews, onboarding workflows, and customer support all rely on interpreting fragmented information spread across multiple formats and systems. When that context is incomplete or stale, automation becomes even more challenging. When it’s clean and structured, entire workflows can move from human-in-the-loop to truly autonomous.
Beyond regulated industries, the impact extends across go-to-market and internal operations. Sales enablement depends on accurate product documentation and customer history. Procurement and finance rely on contracts, invoices, and vendor communications. Engineering teams need reliable search across specs, tickets, logs, and incident reports.
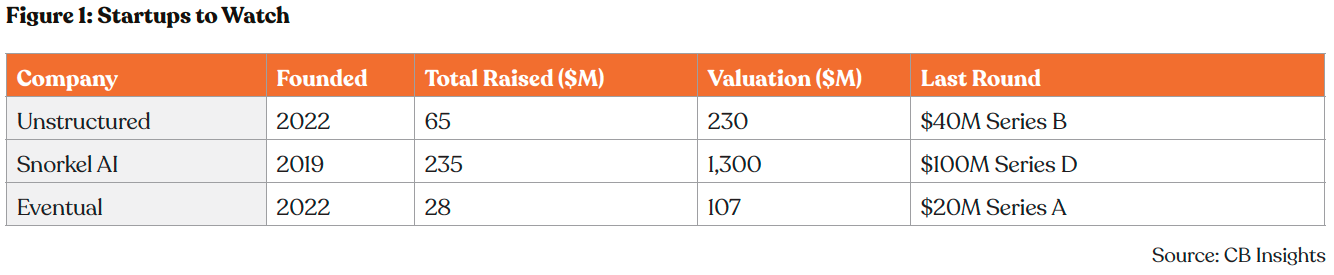
Companies are taking different approaches to solving the unstructured data challenge. California-based Unstructured provides continuous data pipelines over batch processing. Legacy ETL runs on schedules such as daily, hourly, or at best, every 15 minutes. Modern AI workflows demand continuous data sync. Unstructured’s enterprise platform extracts data from existing databases and transforms it into LLM-ready formats in near real-time before loading into vector databases. It helps models stay current with authoritative information rather than operating on stale snapshots. This approach has helped Unstructured dominate the AI data preprocessing space with support for 60+ file types and 50+ connectors, creating switching costs as enterprises integrate these capabilities into their LLM workflows.
Founded in 2019, Snorkel AI is taking a different approach. The company is pioneering the shift from manual data labeling to programmatic data development for AI. Snorkel AI has established itself as a leader in programmatic data labeling and synthetic data generation, with proven enterprise deployments at Fortune 500 companies including BNY Mellon and Experian. With its approach, Snorkel has helped companies shrink the time to prepare and label their raw data from months down to weeks.
California-based Eventual is creating a new foundation for AI infrastructure that’s purpose-built for multimodal data. Its open-source, high-performance, Python-native engine, called Daft, unifies processing across modalities. Companies like AWS, Essential AI Labs, and Together.ai use it in production to process petabytes for AI models, autonomous vehicles, and recommendation systems.
Context is Everything

For decades, enterprise software has been optimized to record outcomes, not decisions. For instance, CRMs track closed deals, ERPs log transactions, and ticketing systems mark issues as resolved. What none of them capture is how those outcomes came to be — the judgment calls, exceptions, and informal reasoning that actually drive results. In the agentic era, the core focus shifts from static records to the live ‘decision fabric’ that lets AI reason about who did what, why, and in which context. That fabric is the context graph.
Here is what keeps enterprise AI teams up at night. Their agents are simultaneously too confident and completely clueless. An AI assistant can flawlessly execute a refund workflow it has never seen, citing policy documentation with precision, yet approve a discount that violates organization’s sales team norm. It knows the rules but has no idea how the game is actually played. Against this backdrop, context graphs are emerging as the missing layer that gives AI systems a sense of how decisions are actually made inside organizations.
The problem isn't training data or model quality. It’s that large language models (LLMs) are stateless by design. Every interaction starts from scratch. When one asks an LLM-powered agent to evaluate a complex decision, it receives the prompt and relevant documents retrieved through RAG, but no record of how similar decisions were handled in the past. For simple queries like "what's our return policy?", this works fine. For decisions that require judgment informed by experience, it fails.
The industry's first instinct has been to throw better retrieval at the problem. GraphRAG from Microsoft enhances knowledge graphs with LLM-extracted entities and relationships, making it easier to answer questions that require connecting multiple pieces of information. It's impressive technology that genuinely improves on basic vector search, particularly for multi-step reasoning.
But this addresses symptoms, not causes. GraphRAG excels at synthesizing what's written down. But the problem is that a lot of organizational knowledge isn't written down. For instance, the real intelligence like which customers are actually strategic, how escalation patterns shift under pressure, what informal networks solve problems, exists as tribal knowledge scattered across Slack threads, meeting transcripts, and hallway conversations that never get documented.
Vector databases offer another dead end. They excel at semantic similarity but know nothing about causality, precedent, or change over time.
What Context Graphs Actually Solve
Context graphs represent a different approach entirely. At its core, a context graph is a structured representation of knowledge that captures not just what entities are and how they relate, but the full context in which those relationships exist and matter. Every time an agent executes a decision, approves an exception, or routes a task, the system records not just the outcome but the full decision trace like which data sources were consulted, what constraints were checked, who was involved, what was approved, and most importantly what context justified that specific action at that specific moment. Over time, these decision traces accumulate into a rich map of how your organization actually operates, not how the policy manual says it should.
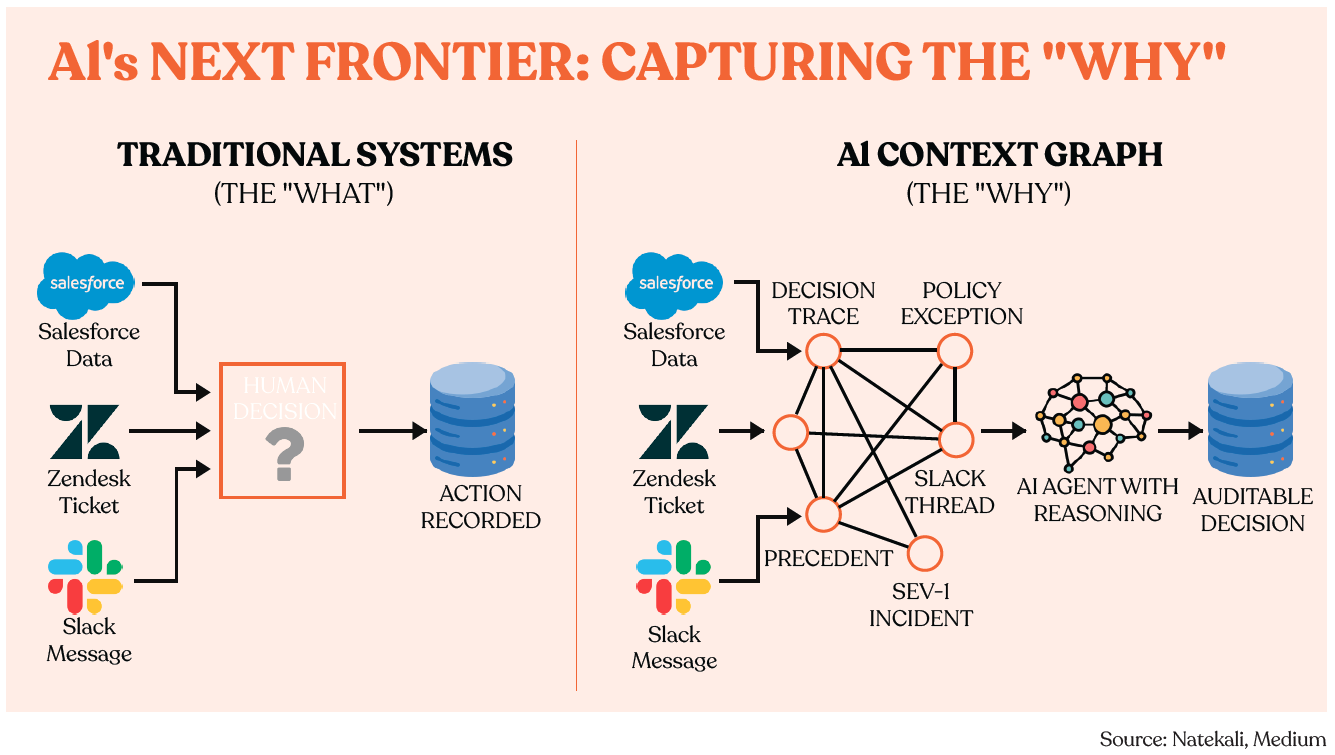
The power emerges from compounding. The first month, the context graph is thin with lots of nodes but few meaningful patterns. Six months in, it starts recognizing patterns like certain customer profiles consistently get different treatment, or that approval patterns shift around quarter-end.
This is qualitatively different from knowledge graphs, which map entities and relationships but rarely capture time and context. A knowledge graph knows Jake reports to the VP of Sales. A context graph knows that Jake's approval patterns changed after Q2, or that he tends to escalate differently for enterprise deals, or that his exceptions usually get approved when backed by customer health metrics but rejected when they're purely competitive responses.
Building context graphs comes with real challenges. The difficulty is not primarily about modeling or scale, but about time. Context is only meaningful within a specific window. Every relationship, role, and rule changes. For instance, Jake was a Director until June, then became a VP. The pricing policy allowed 30% discounts last quarter, but only 25% after the new fiscal year. A context graph has to know not just what was true, but when it was true.
If the context graph can't precisely track what was true when, it will confidently produce wrong recommendations by applying current state to historical decisions or vice versa. Most graph databases treat time as just timestamps on nodes rather than validity windows baked into the data model. This works fine for static knowledge but not for operational context.
The second technical hurdle is identity resolution across systems. The same approval might appear in Salesforce as an opportunity stage change, in Slack as a thumbs-up emoji, in email as "sounds good," and in ERP as a status update. Context graphs need to understand these are all the same decision made by the same person at the same moment, despite different identifiers, formats, and representations across systems.
Startups to Watch
The companies positioned to build dominant context graphs share a specific structural advantage. They sit in the execution path where decisions get made, not in post-facto analysis where decisions get recorded.
Systems of agents platforms are already orchestrating workflows, which means they see the full decision context in real-time. When an AI agent pulls data from three systems, checks five policies, and executes an approval, platforms like Glean observe the entire information flow. They can capture what was known, what was considered, and what was decided with full fidelity at the moment it happens.
Observability companies building for AI agents have a parallel advantage. Just as Datadog captured value by making application behavior visible, companies like Arize are building the monitoring layer that makes agent reasoning inspectable. They're already logging what agents consider, which tools they use, where they fail. Extending that into persistent context graphs is a natural evolution of the same infrastructure.
Vertical AI companies in high-stakes domains have the most direct path. In areas like healthcare, financial services, or legal, where decisions require auditable reasoning, capturing context is regulatory necessity. This creates natural forcing functions that justify the engineering investment and data hygiene required to build production-grade context graphs.
The ultimate question isn't whether context graphs emerge—they will, because AI agents need them to function reliably. The question is whether they become a new category of proprietary platform, or a feature that gets subsumed into existing systems of record.

What’s a Rich Text element?
Heading 3
Heading 4
Heading 5
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
Static and dynamic content editing
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
How to customize formatting for each rich text
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.